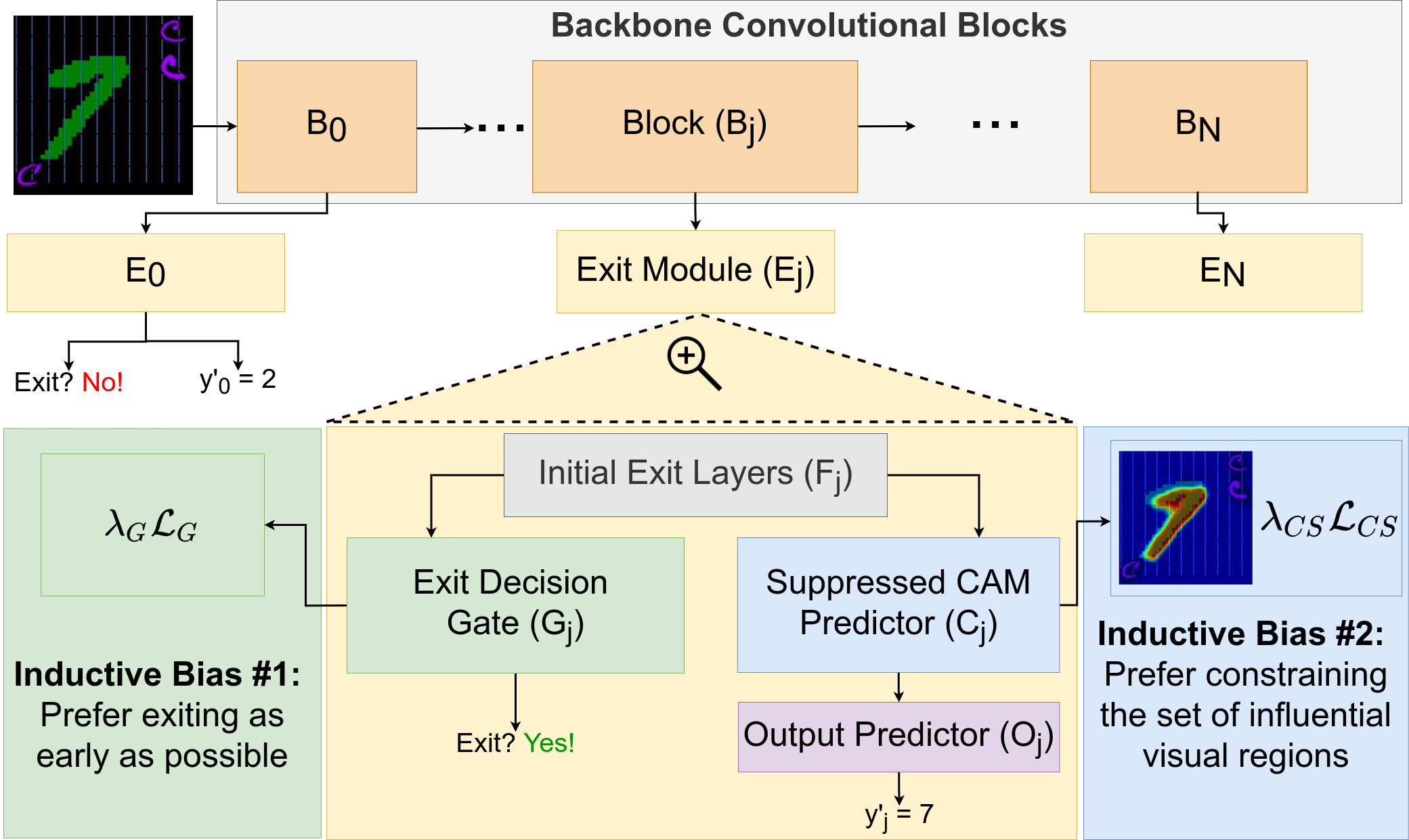
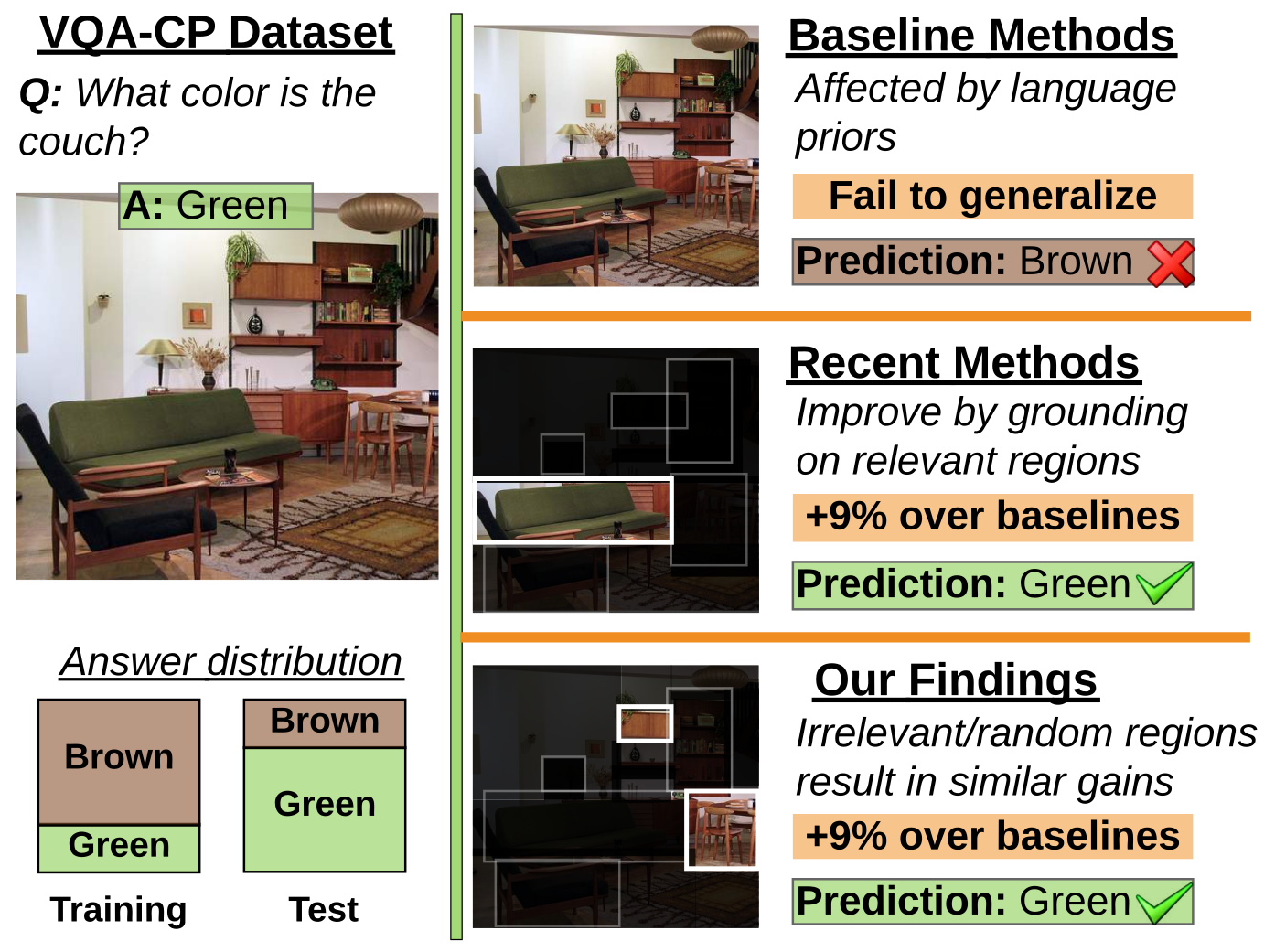
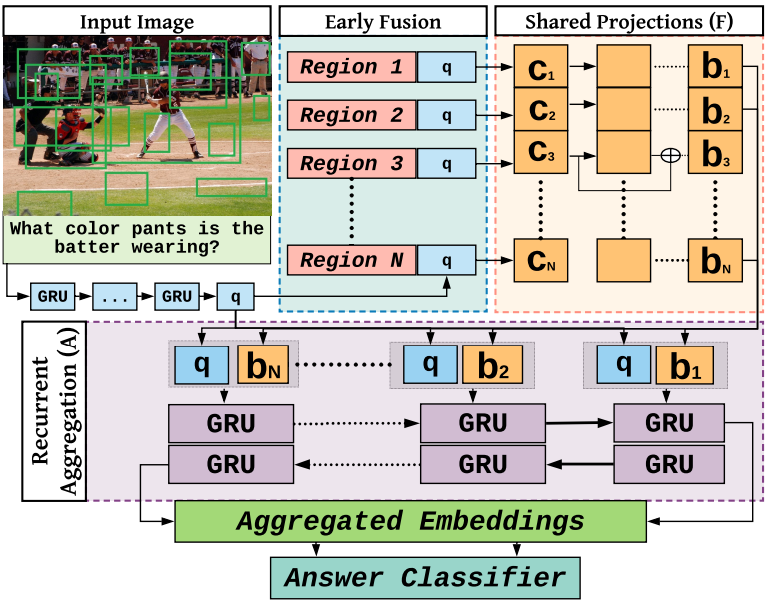
Existing Visual Question Answering (VQA)
methods tend to exploit dataset biases and spurious statistical correlations, instead of
producing right answers for the right reasons. To address this issue, recent bias mitigation
methods for VQA propose to incorporate visual
cues (e.g., human attention maps) to better
ground the VQA models, showcasing impressive gains. However, we show that the performance
improvements are not a result of improved visual grounding, but a regularization
effect which prevents over-fitting to linguistic priors. For instance, we find that it is not
actually necessary to provide proper, humanbased cues; random, insensible cues also result in
similar improvements. Based on this
observation, we propose a simpler regularization scheme that does not require any external
annotations and yet achieves near state-of-the-art performance on VQA-CPv2.
Association for Computational Linguistics (ACL 2020)
Paper
Code
Bibtex
@inproceedings{shrestha-etal-2020-negative,
title = "A negative case analysis of visual grounding methods for {VQA}",
author = "Shrestha, Robik and
Kafle, Kushal and
Kanan, Christopher",
booktitle = "Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.acl-main.727",
pages = "8172--8181"
}